分布式幂等性如何设计?
在高并发场景的架构里,幂等性是必须得保证的。比如说支付功能,用户发起支付,如果后台没有做幂等校验,刚好用户手抖多点了几下,于是后台就可能多次受到同一个订单请求,不做幂等很容易就让用户重复支付了,这样用户是肯定不能忍的。
解决方案
- 查询和删除不在幂等讨论范围,查询肯定没有幂等的说,删除:第一次删除成功后,后面来删除直接返回0,也是返回成功。
- 建唯一索引,唯一索引或唯一组合索引来防止新增数据存在脏数据 (当表存在唯一索引,并发时新增异常时,再查询一次就可以了,数据应该已经存在了,返回结果即可)。
- token机制,由于重复点击或者网络重发,或者nginx重发等情况会导致数据被重复提交。前端在数据提交前要向后端服务的申请token,token放到 Redis 或 JVM 内存,token有效时间。提交后后台校验token,同时删除token,生成新的token返回。redis要用删除操作来判断token,删除成功代表token校验通过,如果用select+delete来校验token,存在并发问题,不建议使用。
- 悲观锁
1
select id ,name from table_# where id='##' for update;
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用(另外还要考虑id是否为主键,如果id不是主键或者不是 InnoDB 存储引擎,那么就会出现锁全表)。
- 乐观锁,给数据库表增加一个version字段,可以通过这个字段来判断是否已经被修改了
1
update table_xxx set name=#name#,version=version+1 where version=#version#
- 分布式锁,比如 Redis 、 Zookeeper 的分布式锁。单号为key,然后给Key设置有效期(防止支 付失败后,锁一直不释放),来一个请求使用订单号生成一把锁,业务代码执行完成后再释放锁。
- 保底方案,先查询是否存在此单,不存在进行支付,存在就直接返回支付结果。
说说你对分布式事务的了解
分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在微服务架构中,几乎可以说是无法避免。
首先要搞清楚:ACID、CAP、BASE理论。
**ACID **
指数据库事务正确执行的四个基本要素:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
CAP
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance)。
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
- 一致性:在分布式系统中的所有数据备份,在同一时刻是否同样的值。
- 可用性:在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
- 分区容忍性:以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
BASE理论
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
、你知道哪些分布式事务解决方案?
我目前知道的有五种:
- 两阶段提交(2PC)
- 三阶段提交(3PC)
- 补偿事务(TCC=Try-Confirm-Cancel)
- 本地消息队列表(MQ)
- Sagas事务模型(最终一致性) 说完上面五种,面试官一般都会继续问下面这几个问题(可能就问一两个,也可能全部问)。
两阶段提交
两阶段提交2PC是分布式事务中最强大的事务类型之一,两段提交就是分两个阶段提交:
第一阶段询问各个事务数据源是否准备好。
第二阶段才真正将数据提交给事务数据源。
为了保证该事务可以满足ACID,就要引入一个协调者(Cooradinator)。其他的节点被称为参与者(Participant)。协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务进行提交。
处理流程如下:
阶段一
- 协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待答复。
- 各参与者执行事务操作,将 undo 和 redo 信息记入事务日志中(但不提交事务)。
- 如参与者执行成功,给协调者反馈 yes,否则反馈 no。
阶段二
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(rollback)消息;否则,发送提交(commit)消息。
两种情况处理如下:
情况1:当所有参与者均反馈 yes,提交事务 - 协调者向所有参与者发出正式提交事务的请求(即 commit 请求)。
- 参与者执行 commit 请求,并释放整个事务期间占用的资源。
- 各参与者向协调者反馈 ack(应答)完成的消息。
- 协调者收到所有参与者反馈的 ack 消息后,即完成事务提交。 情况2:当有一个参与者反馈 no,回滚事务
- 协调者向所有参与者发出回滚请求(即 rollback 请求)。
- 参与者使用阶段 1 中的 undo 信息执行回滚操作,并释放整个事务期间占用的资源。
- 各参与者向协调者反馈 ack 完成的消息。
- 协调者收到所有参与者反馈的 ack 消息后,即完成事务。 问题
- 性能问题
所有参与者在事务提交阶段处于同步阻塞状态,占用系统资源,容易导致性能瓶颈。 - 可靠性问题 如果协调者存在单点故障问题,或出现故障,提供者将一直处于锁定状态。
- 数据一致性问题:在阶段 2 中,如果出现协调者和参与者都挂了的情况,有可能导致数据不一致。
优点:尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证 强一致)。 缺点:实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景。
什么是三阶段提交?
三阶段提交是在二阶段提交上的改进版本,3PC最关键要解决的就是协调者和参与者同时挂掉的问题,所以3PC把2PC的准备阶段再次一分为二,这样三阶段提交。
处理流程如下 :
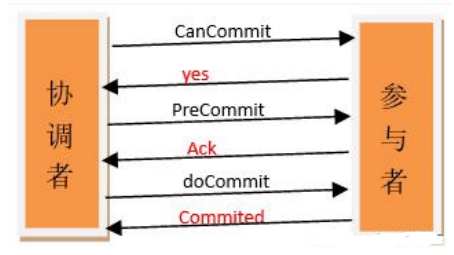
阶段一
- 协调者向所有参与者发出包含事务内容的 canCommit 请求,询问是否可以提交事务,并等待所有参与者答复。
- 参与者收到 canCommit 请求后,如果认为可以执行事务操作,则反馈 yes 并进入预备状态,否则反馈 no。
阶段二
协调者根据参与者响应情况,有以下两种可能。
情况1:
所有参与者均反馈 yes,协调者预执行事务
- 协调者向所有参与者发出 preCommit 请求,进入准备阶段。
- 参与者收到 preCommit 请求后,执行事务操作,将 undo 和 redo 信息记入事务日志中(但不提交事务)。
- 各参与者向协调者反馈 ack 响应或 no 响应,并等待最终指令。
情况2:
只要有一个参与者反馈 no,或者等待超时后协调者尚无法收到所有提供者的反馈,即中断事务
- 协调者向所有参与者发出 abort 请求。
- 无论收到协调者发出的 abort 请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务。 阶段三
该阶段进行真正的事务提交,也可以分为以下两种情况。
情况 1:所有参与者均反馈 ack 响应,执行真正的事务提交
- 如果协调者处于工作状态,则向所有参与者发出 do Commit 请求。
- 参与者收到 do Commit 请求后,会正式执行事务提交,并释放整个事务期间占用的资源。
- 各参与者向协调者反馈 ack 完成的消息。
- 协调者收到所有参与者反馈的 ack 消息后,即完成事务提交。 情况2:只要有一个参与者反馈 no,或者等待超时后协调组尚无法收到所有提供者的反馈,即回滚 事务。
- 如果协调者处于工作状态,向所有参与者发出 rollback 请求。
- 参与者使用阶段 1 中的 undo 信息执行回滚操作,并释放整个事务期间占用的资源。
- 各参与者向协调组反馈 ack 完成的消息。
- 协调组收到所有参与者反馈的 ack 消息后,即完成事务回滚。
优点:相比二阶段提交,三阶段提交降低了阻塞范围,在等待超时后协调者或参与者会中断事务。
避免了协调者单点问题。阶段 3 中协调者出现问题时,参与者会继续提交事务。
缺点:数据不一致问题依然存在,当在参与者收到 preCommit 请求后等待 do commite 指令时,
此时如果协调者请求中断事务,而协调者无法与参与者正常通信,会导致参与者继续提交事务,造成数据不一致。
什么是补偿事务?
本地消息表(异步确保)
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行
处理,这种思路是来源于ebay。我们可以从下面的流程图中看出其中的一些细节:
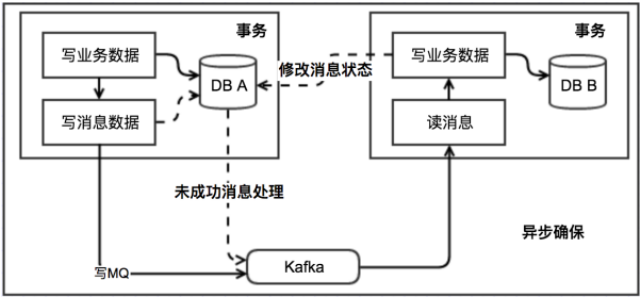
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有
靠谱的自动对账补账逻辑,这种方案还是非常实用的。
这种方案遵循BASE理论,采用的是最终一致性,笔者认为是这几种方案里面比较适合实际业务场景的,即不会出现像2PC那样复杂的实现(当调用链很长的时候,2PC的可用性是非常低的),也不会像TCC那样可能出现确认或者回滚不了的情况。
**优点: **一种非常经典的实现,避免了分布式事务,实现了最终一致性。在 .NET中 有现成的解决方案。
**缺点: **消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
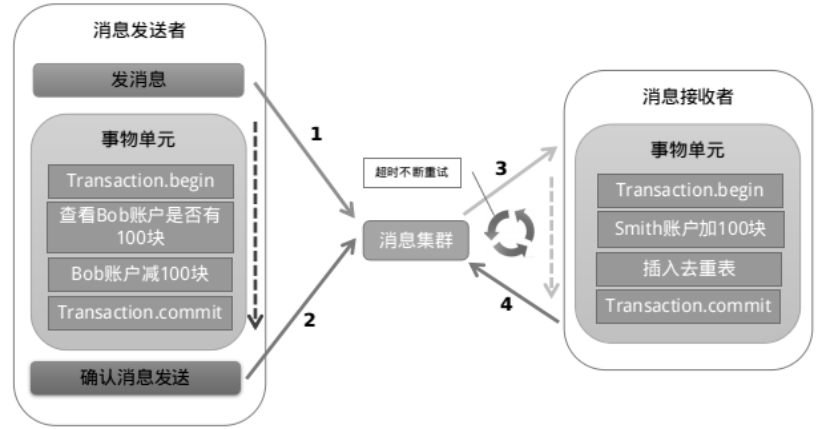
以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段Prepared消息,会拿到消息的地址。 第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息
发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
优点:实现了最终一致性,不需要依赖本地数据库事务。
缺点:实现难度大,主流MQ不支持,RocketMQ事务消息部分代码也未开源。
分布式ID生成有几种方案?
分布式ID的特性
- 唯一性:确保生成的ID是全网唯一的。
- 有序递增性:确保生成的ID是对于某个用户或者业务是按一定的数字有序递增的。
- 高可用性:确保任何时候都能正确的生成ID。
- 带时间:ID里面包含时间,一眼扫过去就知道哪天的交易。
分布式ID生成方案
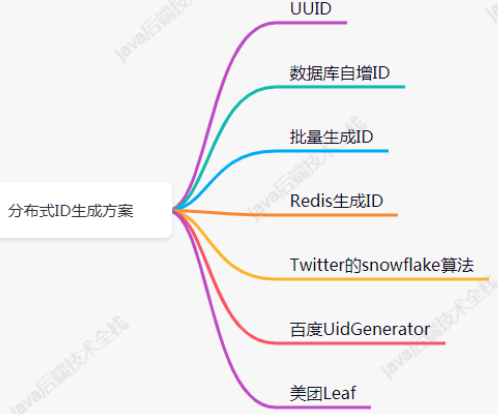
- UUID
算法的核心思想是结合机器的网卡、当地时间、一个随记数来生成UUID。- 优点:本地生成,生成简单,性能好,没有高可用风险
- 缺点:长度过长,存储冗余,且无序不可读,查询效率低
- 数据库自增ID
使用数据库的id自增策略,如 MySQL 的 auto_increment。并且可以使用两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。- 优点:数据库生成的ID绝对有序,高可用实现方式简单
- 缺点:需要独立部署数据库实例,成本高,有性能瓶颈
- 批量生成ID
一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。- 优点:避免了每次生成ID都要访问数据库并带来压力,提高性能
- 缺点:属于本地生成策略,存在单点故障,服务重启造成ID不连续
- Redis生成ID
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。- 优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
- 缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作量比较大。 考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长都是 5。
- Twitter的snowflake算法(重点)
Twitter 利用 zookeeper 实现了一个全局ID生成的服务 Snowflake
如上图的所示,Twitter 的 Snowflake 算法由下面几部分组成:
1位符号位:
由于 long 类型在 java 中带符号的,最高位为符号位,正数为 0,负数为 1,且实际系统中所使用的ID一般都是正数,所以最高位为 0。
41位时间戳(毫秒级): 需要注意的是此处的 41 位时间戳并非存储当前时间的时间戳,而是存储时间戳的差值(当前时间戳 - 起始时间戳),这里的起始时间戳一般是ID生成器开始使用的时间戳,由程序来指定,所以41位毫秒时间戳最多可以使用 (1 « 41) /(1000x60x60x24x365) = 69年 。
10位数据机器位: 包括5位数据标识位和5位机器标识位,这10位决定了分布式系统中最多可以部署 1 « 10 = 1024 s个节点。超过这个数量,生成的ID就有可能会冲突。
12位毫秒内的序列:
这 12 位计数支持每个节点每毫秒(同一台机器,同一时刻)最多生成 1 « 12= 4096个ID加起来刚好64位,为一个Long型。
- 优点:高性能,低延迟,按时间有序,一般不会造成ID碰撞
- 缺点:需要独立的开发和部署,依赖于机器的时钟
- 百度UidGenerator UidGenerator是百度开源的分布式ID生成器,基于于snowflake算法的实现,看起来感觉还行。不过,国内开源的项目维护性真是担忧。
- 美团Leaf Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
限流算法有哪些?
限流算法有四种常见算法:
- 计数器算法(固定窗口)
- 滑动窗口
- 漏桶算法
- 令牌桶算法
计数器算法(固定窗口)
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
此算法在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性和线程安全即可轻松实现。
这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题.
假设1min内服务器的负载能力为100,因此一个周期的访问量限制在100,然而在第一个周期的最后5秒和下一个周期的开始5秒时间段内,分别涌入100的访问量,虽然没有超过每个周期的限制量,但是整体上10秒内已达到200的访问量,已远远超过服务器的负载能力,由此可见,计数器算法方式限流对于周期比较长的限流,存在很大的弊端。
滑动窗口算法
滑动窗口算法是将时间周期分为N个小周期,分别记录每个小周期内访问次数,并且根据时间滑动删除过期的小周期。
如下图,假设时间周期为1min,将1min再分为2个小周期,统计每个小周期的访问数量,则可以看到,第一个时间周期内,访问数量为75,第二个时间周期内,访问数量为100,超过100的访问则被限流掉了。
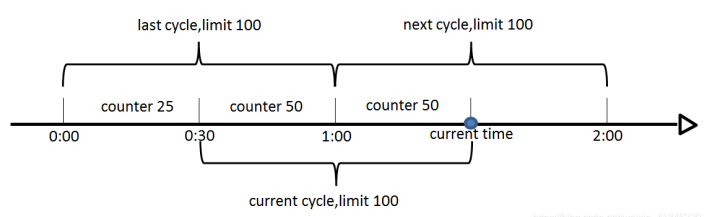
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
此算法可以很好的解决固定窗口算法的临界问题。
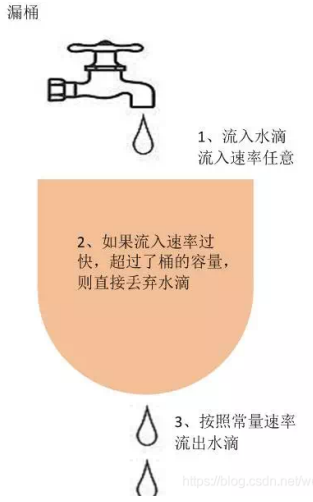
漏桶算法
漏桶算法是访问请求到达时直接放入漏桶,如当前容量已达到上限(限流值),则进行丢弃(触发限流策略)。漏桶以固定的速率进行释放访问请求(即请求通过),直到漏桶为空。
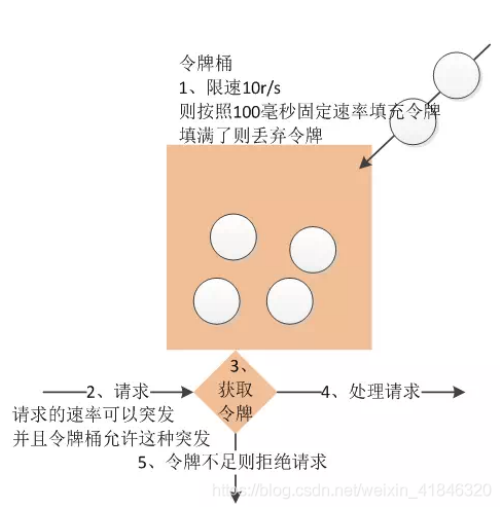
令牌桶算法
令牌桶算法是程序以r(r=时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满,请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略
数据库如何处理海量数据?
对数据库进行:分库分表,主从架构,读写分离。
水平分库/分表,垂直分库/分表。
水平分库/表,各个库和表的结构一模一样。
垂直分库/表,各个库和表的结构不一样。
读写分离:主机负责写,从机负责读。
如何提高系统的并发能力?
- 使用分布式系统。
- 部署多台服务器,并做负载均衡。
- 使用缓存(Redis)集群。
- 数据库分库分表 + 读写分离。
- 引入消息中间件集群。